Mealwrm

Description
Mealwrm is a meal planning app that can take a URL from an online recipe and import the directions and ingredients. You can then use the imported recipes to plan meals for the week and grocery shop with a single ingredient list.
Background
My partner and I like to cook a lot. We frequently use recipes from a wide variety of food blogs—Serious Eats, Half Baked Harvest, and New York Times Cooking, to name a few. Many of these blogs have little "recipe box" functionality, where you can save recipes within the site. You can't, however, save or add recipes from other websites, which is a major bummer when you're trying to branch out. Also, as much respect as I have for the blogger lifestyle, most recipes have way too non-recipe content associated with them1. Mealwrm parses out the relevant recipe information and collates everything together into a nice little shopping list, and even shows updates to the lists in realtime so multiple people can grocery shop simultaneously.
Engineering
Mealwrm's probably one of the more built-out apps that I've worked on as a side quest. One of the main engineering challenges with it was (and is) the web scraping utility and its ability to pull ingredients and directions from an arbitrary website.
For the scrapin', as part of a server request that receives the site's URL, we fetch the website content with a simple GET request. Since this is all on the server, we parse the DOM with the node utility jsdom, which parses an HTML string into Element objects just like in the browser. To find the ingredients lists, we flatten the entire DOM into text nodes2, and then look for any nodes that have the keyword "ingredients." If found, we look up the tree at the parent element, and then attempt to find a sibling ordered list element (i.e. ol). If found, we grab the list and return the contents of each item as an ingredient. Finding the directions is done in much the same way.
/**
* Pulls out the list items from the list element node
*/
const findListItems = (element, type = 'UL') => {
let list = null;
// If the next node is a list
if (element.nodeName === type) {
list = element;
// Otherwise see if the next node has a list child
} else if (element.querySelectorAll(type).length) {
const listChildren = element.querySelectorAll(type);
[list] = listChildren;
}
let items = [];
if (list) {
const listItems = [...list.childNodes];
items = listItems.filter((item) => item.nodeName === 'LI' || item.nodeName === 'P').map((item) => item.textContent);
}
return [items, list];
};
/**
* Search the dom for a list of ingredients
*/
export const findIngredientsList = (dom) => {
const { document } = dom.window;
const textNodes = textNodesUnder(document.body);
// Find a text node with 'ingredients'
const ingredientsNodeIndex = textNodes.findIndex((n) => n.textContent.toLowerCase() === 'ingredients');
// Container to hold the found ingredients
const ingredients = [];
if (ingredientsNodeIndex > -1) {
let element = textNodes[ingredientsNodeIndex].parentElement;
let newIngredients = [];
const maxLoops = 10;
const maxSiblings = 3; // Check a maximum of 3 siblings without finding any before calling it quits
let loop = 0;
do {
const nextSibling = element.nextElementSibling;
if (nextSibling) {
[newIngredients] = findListItems(nextSibling);
ingredients.push(...newIngredients);
element = nextSibling;
// Reset the loop if we found ingredients
if (newIngredients.length) loop = 0;
} else {
newIngredients = [];
}
// Safeguard against while
loop += 1;
// Continue checking next sibling until we don't find any list items
} while ((newIngredients.length || loop < maxSiblings) && loop < maxLoops);
}
const trimmed = ingredients.map((item) => item.replace(/\s+/g, ' ').trim()).filter((item) => item);
return trimmed;
};It's certainly not perfect, and admittedly not that sophisticated. For example, it misses ingredient lists when websites don't use explicit ol elements, but for the most part it fairs pretty well.
"Arbitrary text parsing? Why not just use ChatGPT?", you ask. Well, I did use ChatGPT, and it works incredibly3 well...usually. The problem with ChatGPT is we have to feed it an entire webpage of text, which can (1) take a long time to analyze, and (2) cost a lot of cash-money. I think one area of future work is combining both methods, and identifying a main block of text to then feed into ChatGPT (or other AI text analysis tool). But for now, this has served us pretty darn well.
The other interesting aspect to this project was figuring out the best data models for storing recipes and various components of the recipes. I usually use MongoDB for database stuff, and Mealwrm is no exception. In short, we have a UserPlan, which represents a date range and list of recipes. Each PlanRecipe is actually more like a database link to a static Recipe, which has fields like name, image, url, lists (ingredients), and directionsLists. That way we can reuse recipes again in other plans. Furthermore, each ingredient in a plan-based recipe is linked to specific IngredientCheck item, again so we can associate the same recipe with different plans and states of ingredients being checked.
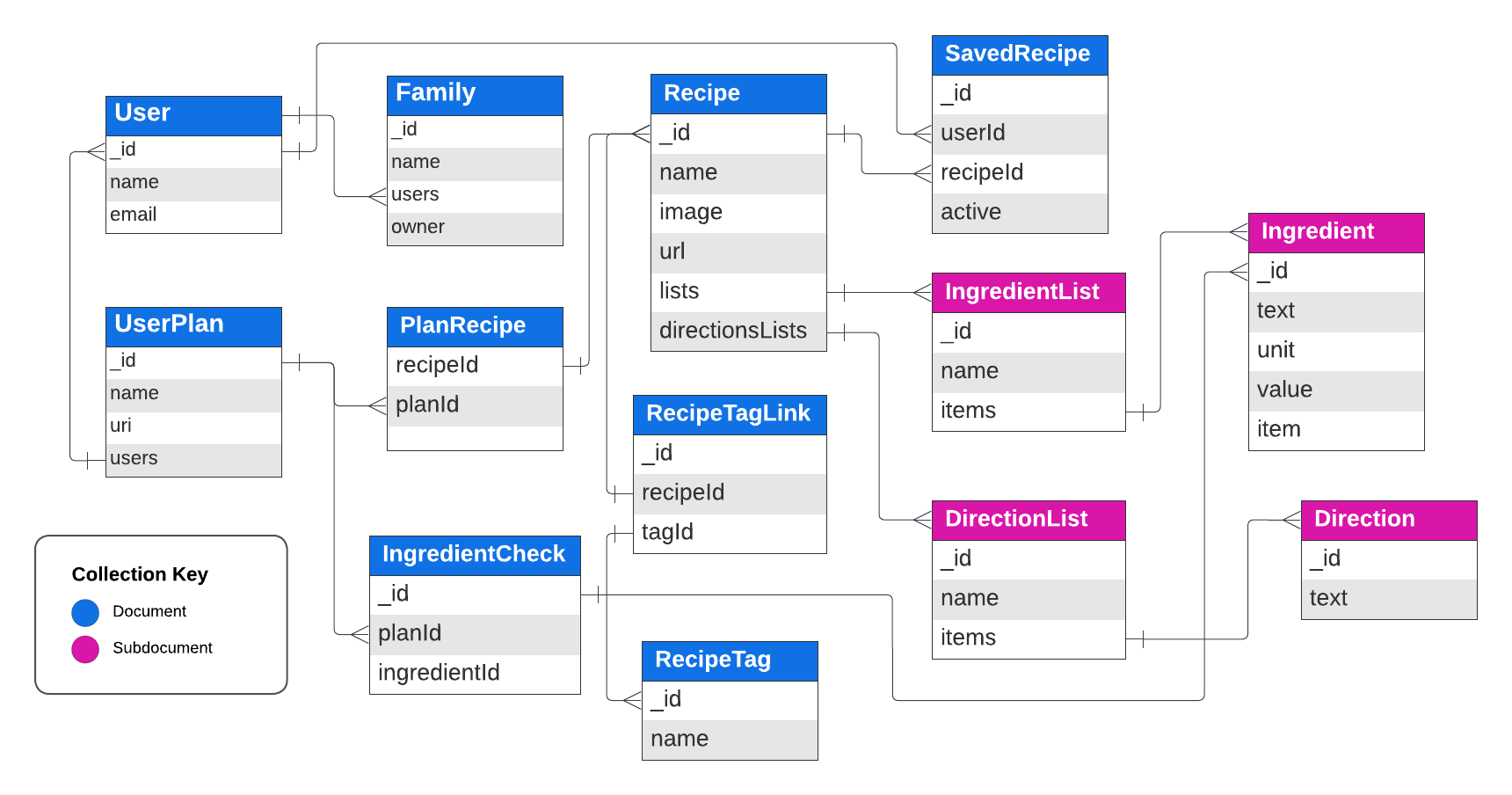
Finally, a feature that is built out to some extent but not necessarily dialed, are families, i.e. groups of users that can share recipes and plans.
Stack
Backend
Mealwrm's backend was originally built with good ol' fashioned ExpressJS. Recently I've been into NextJS, so I migrated and refactored4 to NextJS and now deploy via Vercel. As stated above, I use MongoDB for the database layer, hosted on MongoDB cloud. To manage live syncing of ingredients data, I previously used socket.io which worked really well. Unfortunately, due to the "Edge" ephemeral environments that Vercel utilizes for NextJS, socket.io is a no-go. Now I use the free tier of pusher.
Frontend
Originally Mealwrm was built with Create React App, now we've still got React but through NextJS's rendering framework. For styling I use RebassJS, which is a low-level framework on styled-components and styled-system. For the search functionality, I use Algolia (free tier life).